新闻
现金九游体育app平台从而缩小了模子在密集任务中的阐扬-九游体育「NineGame Sports」官方网站
刚刚,Meta 发布了全新开源视觉模子 DINOv3 ——
初次讲明了自监督学习模子梗概辞世俗任务中越过弱监督学习模子。
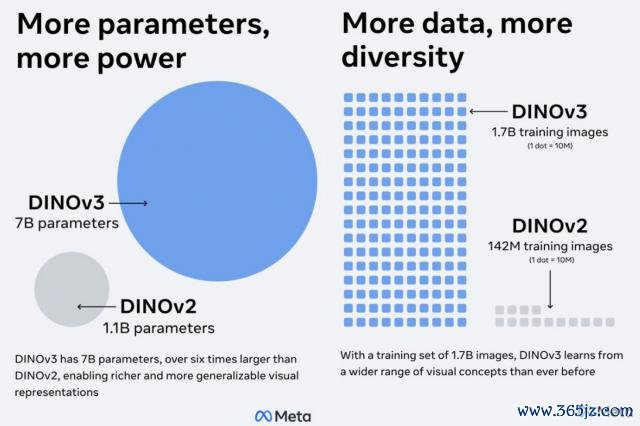
DINOv3 选拔无标注步调,将数据范围彭胀至17 亿张图像、模子范围彭胀至70 亿参数,并能高效赞助数据标注稀缺、资本不菲或无法获取的应用场景。

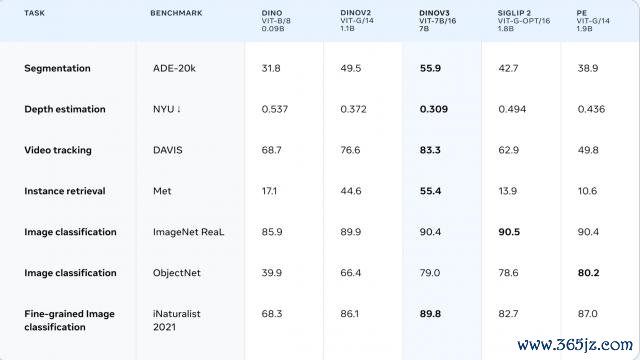
DINOv3 不仅在缺少标注或跨领域的场景(相聚图像与卫星影像)中阐扬出完全的性能开端,还在算计机视觉三大中枢任务(分类、检测、分割)上已毕了 SOTA。
网友默示:我还觉得你们照旧不成了,好在你们终于搞出点东西来了。

算计机视觉的自监督学习
提及算计机视觉,就绕不开李飞飞素养鼓动的 ImageNet 和大范围标注数据。
关联词,跟着数据量的激增以及应用场景不绝彭胀,标注资本和可获取性成为了制约视觉模子通用性的主要身分。
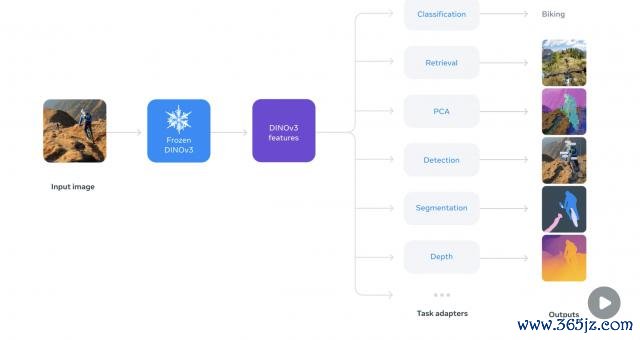
基于这一想路,DINOv3 选拔了改进的自监督学习步调,专注于生成高质地且高差异率的视觉特征,为卑劣视觉任务提供刚劲的主干模子(backbone)赞助。
通过这一步调,DINOv3初次已毕了单一冻结视觉主干相聚(Single Frozen Vision Backbone)在多项密集谋略任务(Dense Prediction Tasks)中越过非常化治理有贪图的性能。
那么,DINOv3 是奈何作念到的?
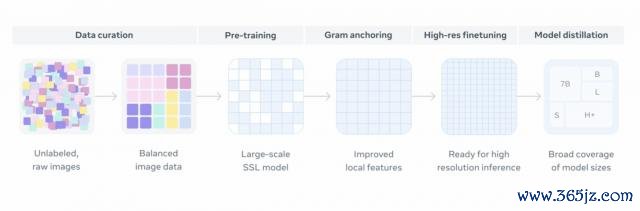
总的来说,DINOv3 的老成过程分为两个主要阶段:
DINOv3 在一个宏大且用心构建的数据集上进行大范围自监督老成,从而学习到通用且高质地的视觉默示
引入名为" Gram anchoring "的新步调来治理老成中密集特征图的退化问题,在不影响全局特征的同期,显耀升迁局部特征的质地
具体来说,盘问者开端构建了一个包含约17 亿张图片的预老成数据集。
这些图片数据主要来自Instagram上的公开图片,以及极少来自ImageNet的图片。
在对数据集进行分类、采样后,盘问者选拔判别式自监督(Discriminative Self-supervised),通过 Sinkhorn-Knopp 算法和 Koleo 正则结识特征分散,已毕了细粒度又郑重的密集特征学习。
此外,在经受 DINOv2 胜利步调的基础上,DINOv3 将模子参数从 11 亿彭胀至 70 亿,以增强主干相聚的默示才调,从而梗概从海量图像中学习更丰富、细粒度的视觉特征。
比拟 v2,DINOv3 在老成计谋上引入了 RoPE-box jittering,使模子对差异率、规范和长宽比变化更具鲁棒性,同期保留多剪辑老成和恒定学习率 +EMA 教师动量优化的作念法,确保老成结识且高效。
在大范围老成中,DINOv3 的 70 亿参数模子不错通过永劫辰老成显耀升迁全局任务性能,因此盘问者在最初就寄但愿于永劫辰老成。
关联词,密集谋略任务(如图像分割)时时会跟着老成迭代次数的增多而着落,而这种退化主要源于 patch-level(补丁级别)特征的一致性丧失:
跟着老成进行,正本定位考究的 patch 特征迟缓出现不干系 patch 与参考 patch 相同渡过高的表象,从而缩小了模子在密集任务中的阐扬。
为了大意这一问题,盘问团队提议了" Gram anchoring "步调,即通过将学生模子的 patch Gram 矩阵贴近早期老成阶段阐扬优异的教师模子的 Gram 矩阵,来保握 patch 间的相对相同性,而不戒指特征自己的解放抒发。
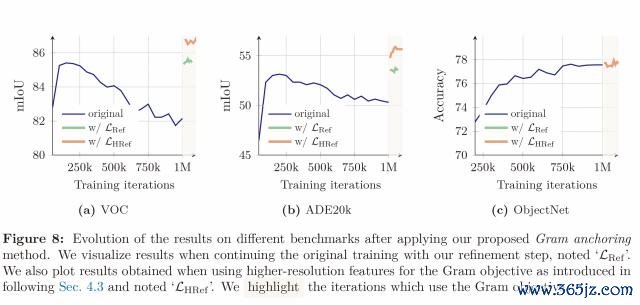
执行标明,在应用 Gram anchoring 后,ADE20k 分割任务有着显耀的升迁,且老成结识性赫然增强。
这标明保握 patch-level 一致性与学习判别性全局特征之间不错灵验和解,而在有针对性的正则化下,永劫辰老成也不再断送密集任务阐扬。
此外,通过将高差异率图像输入到 Gram 教师并下采样至与学生输出疏通的尺寸,仍然赢得了平滑且一致的 patch 特征图。
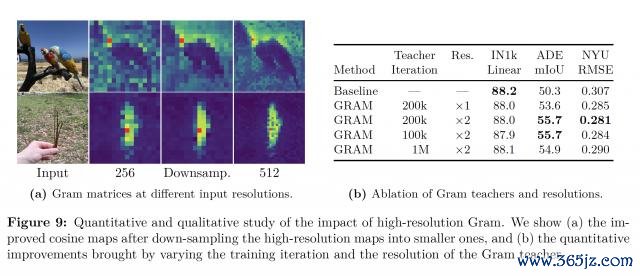
执行成果自满,即便经过下采样,高差异率特征中优厚的 patch-level 一致性仍得以保留,从而生成愈加平滑、连贯的 patch 默示。
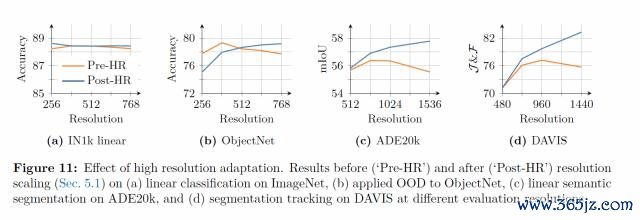
终末,由于 DINOv3 在最初老成时使用了相对较低的差异率(256 × 256),为了让模子符合高差异率的图像场景,盘问团队在老成后增多了一个"高差异率符合步调",从而让模子在学会处理更大尺寸图像的同期,还能保握性能结识。
在这一符合步调中,DINOv3 承接了"羼杂差异率"(mixed resolutions)计谋与 Gram anchoring 步调,使模子在处理更大、更复杂的图像时仍能保握结识且密致的特征默示,同期兼顾全局任务与密集谋略任务的性能。
终末,为了考据 DINOv3 的性能,盘问团队在包含密集特征、全局特征任务在内的多个算计机视觉任务上对 DINOv3 7B 模子进行了评估。
就像咱们在开端提到的,DINOv3 在语义分割、单目深度测度、非参数步调、3D 对应测度等任务中已毕了 SOTA。
值得一提的是,由于 DINOv3 刚劲的通用性,它还排斥了盘问东谈主员与建立者为了特定任务而对模子进行微调的必要。
此外,为了便捷社区部署,Meta 还通过蒸馏原生的70 亿参数模子 DINOv3,构建了一个建立环境友好的 v3 模子矩阵:VisionTransformer ( ViT ) 的 Small、Base 和 Large 版块,以及基于 ConvNeXt 的架构。
其中,ViT-H+ 模子在多样任务上取得了接近原始 70 亿参数教师模子的性能。
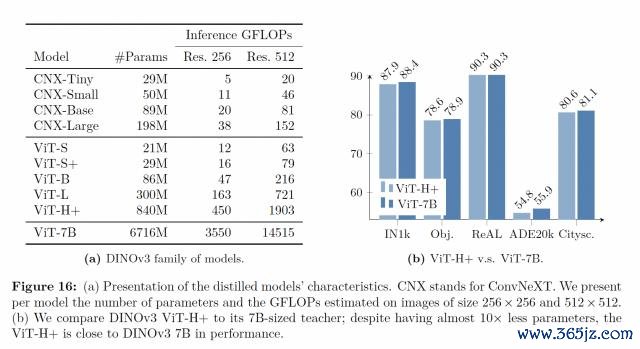
据悉,Meta 也表示将发布具体的蒸馏经由,以便社区梗概在此基础上连续构建与纠正。
DINO 举止
在本体应用中,DINOv3 也展现了刚劲的泛化才调。
举例,在与全国资源盘问所(WRI)和解中,Meta 哄骗 DINOv3 建立了一种算法,梗概哄骗 DINOv3 分析卫星影像,检测受影响生态系统中的树木亏本与地皮哄骗变化。为各人丛林复原和农业管制提供了强有劲的本领赞助。
与 DINOv2 比拟,在使用卫星与航空影像进行老成的情况下,DINOv3 将肯尼亚某地区树冠高度测量的平均时弊从 4.1 米镌汰至 1.2 米。
除此此外,DINOv3 还在多个遥感任务(包括语义地舆空间任务和高差异率语义任务等)中取得了 SOTA。
终末,DINO(Distillation With NO Labels)系列动作 Meta 对视觉领域自监督步调的探索,不错说是一脉相通,束上起下,记号着视觉模子大范围自监督老成的握续跨越。

从 DINO 的初步盘问成见考据,使用100 万张图像老成8000 万参数的模子,
到 DINOv2 中基于1.42亿张图像老成的1B参数模子,SSL 算法的初次胜利彭胀,
再到如今 DINOv3 的70 亿参数和17 亿张图片,
Meta 的这套自监督老成步调有望引颈咱们迈向更大范围、通用性更强,同期愈加精确且高效的视觉认知。
就像 Meta 在本领文档中所形色的:
DINOv3 不仅不错加快现存应用的发展,还可能解锁全新的应用场景,鼓动医疗健康、环境监测、自动驾驶、零卖以及制造业等行业的跨越,从良友毕大范围、更精确、更高效的视觉认知。
参考聚积
[ 1 ] https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
[ 2 ] https://x.com/AIatMeta/status/1956027795051831584
[ 3 ] https://github.com/facebookresearch/dinov3
[ 4 ] https://ai.meta.com/blog/dinov3-self-supervised-vision-model/?utm_source=twitter&utm_medium=organic_social&utm_content=video&utm_campaign=dinov3
[ 5 ] https://ai.meta.com/research/publications/dinov3/
一键三连「点赞」「转发」「注重心」
接待在驳倒区留住你的方针!
— 完 —
� � 但愿了解 AI 家具最新趋势?
量子位智库「AI 100」2025 上半年
「旗舰家具榜」和「改进家具榜」
给出最新参考� �
� � 点亮星标 � �
科技前沿进展逐日见
现金九游体育app平台